




 Qzone
Qzone
 微博
微博
 微信
微信

5月25日,由亿欧举办的“GIIS安防AI创新峰会”在北京千禧酒店盛大召开。其中,眼擎科技CEO朱继志的演讲题目是《eyemore成像引擎芯片:突破安防AI复杂光线瓶颈》。朱继志,毕业于北京大学电子学系。曾任中兴通讯视频开发工程师,在图像视频技术及产品领域有10年的丰富的经验。从小孔成像到现在各种纷繁的影像设备,智能安防很大程度也在依靠图像来进行。朱继志致力于开发新一代超越人眼视觉能力的成像引擎,解决AI视觉在复杂光线下不受干扰高品质成像的核心痛点。
在演讲现场,朱继志从AI安防落地的难点与成像引擎技术做引,通过一段隧道内外复杂光线下成像的demo视频,介绍了AI视觉赛道上图像处理的重点问题。之后从视觉成像的行业发展谈到了芯片产业的崛起,而对于解决复杂光线下的成像问题,朱继志详细阐述了后端算法可以解决一切成像问题的认知误区,以及传统成像技术的副作用。在演讲的最后,朱继志谈到AI芯片产业的发展格局以及眼擎科技为产业赋能的初衷和应用价值。以下便是朱继志的演讲原文(亿欧对该内容有部分删减)。
朱继志:大家上午好,我是朱继志。刚才听到各位嘉宾都讲安防是个非常大的市场,而我们公司做了一个非常小的事情,就是研究在AI视觉里面如何解决复杂光线下的成像问题。传统视觉成像架构积重难返
在座的肯定有不少是做AI图像的,我们现在都讲图像识别率非常高,到95%甚至98%、99%,这些大部分都是实验室的数据,落地到实际场景下经常发现很难识别,首先这是因为图像源的问题。就像淘宝的卖家秀和买家秀一样,很多时候买东西看到的商品演示效果非常好,现场就不行了。其实在语音识别的时候这个问题已经有前车之鉴,到今天为止所有的语音识别都做的非常好,但是有一个问题就是麦克风不行。在常见的生活环境中,比如餐厅里面因为噪声等各种各样的原因,我们现在还见不到能够正常识别的麦克风,而这只是其中的一点。
第二个就是当我们的AI包括很多安防产品开始落地的时候,大家觉得最大的难点是什么?所有人都在说光线差了就不行了,做产品的人会说那是ISP不行,这是现在行业里普遍的一个认知。
我们认为未来的AI视觉的能力,就是相机的能力应该向我们人眼靠齐,甚至比人眼更好。我们公司用了四年时间干这一件事:我们做一项成像引擎的技术,使我们的相机能够在各种各样的环境下来解决成像的问题。我们的眼睛能力最强的不是它的分辨率高,也不是看的很清楚,而是它的环境适应能力特别强。因为人眼是几亿年以来进化的结果,自然可以适应,但是所有的相机和摄像头不具备这个能力。
通过这一段在隧道内外复杂光线下的成像效果视频,我们可以看到隧道内外在黑暗光线下成像对比的反光程度,这是典型的逆光场景。就是在特别晃眼睛的情况下,接下来是一个暗光的场景,在这种情况下eyemore对于颜色还原是非常精准的。在深圳我们有1500多平的光学实验室,在逆光场景下,一般的相机拍摄会觉得暗光和逆光都不行,而我们可以清晰地成像。其实复杂光线的问题一直都存在,我们拍照时也会经常遇到。包括在安防领域。但是以前做这个解决方案属于锦上添花,到了AI之后就变成了必要功能。比如说大家通常会认为在自动驾驶、机器人领域抓拍人脸,拍照光线不好可以不拍,或者可以打灯。以前在安防领域也一样,可以通过打个红外灯等各种各样的方式实现,而现在包括安防、机器人、3D相机、自动驾驶,都需要自动解决复杂光线下自适应的问题,这就是AI导致的前端需求的变化。
如果大家觉得视觉是个赛道,我们来看一下图像处理的环节。其实每个细分市场到它落地的时候都是一个接力赛,在视觉领域里有四棒。从镜头开始到CMOS再到后来的成像、AI识别,大家特别容易关注到的是GPU的事情,只做AI算法,应用很难落地,要做到行业真正的落地,尤其在安防落地,必须要靠整个产业链的进步。其中有一环就是我们做的成像的数据处理,怎么样从CMOS信号变成成像?这种成像包括三部分:一个是要驱动CMOS,第二个是有很多信号处理的算法,第三个是图像算法。很多时候谈到这个能不能通过一个软件GPU来做,答案肯定是不能做的。
传统数码相机的架构,其适应光线的能力特别差,前面也有嘉宾提到过AI架构是3D算法和数据,其实我们也是运用这种类似架构,我们搭了非常大的平台,测试了几百种复杂光线下的场景,因为这类场景不止是在实验室,还有很多不可知、不可预测的场景存在。
其实当我们每看一个细分技术的时候,实际应用中可能会出现一个很长时间无法被解决的问题。大家做安防的都知道,暗光和复杂光非常不好办,我们一定要看一下源头,历史上怎么来的?头部是哪些公司?为什么没有解决?视觉成像最早是胶卷时代,到了八十年代开始,全部转移到日本。我们今天讲安防其实所有的源头都来源于摄影师拿的这个单反相机,相机整个市场被日本垄断了,美国人都不做,我们也没怎么做。我们现在看到的架构完全来源于数码相机的架构,而且这个架构在过去的三十几年里面没有发生任何变化。如果和高品质的相机来比,虽然拥有同样的架构,在安防里这类相机仍是非常低端的产品。提到自动驾驶,汽车里面应用的摄像头比安防更加低端,比手机差的更远。AI赋能产业革新,机器视觉崛起
从AI兴起之后,相机行业有很大的颠覆。以前所有的相机都是给人看,现在开始要给机器看,相机在过去的给人看的阶段,包括佳能、尼康,他们做的大量事情是拍完怎么基于RAW数据修图?而不是从前端改变技术的架构。现在开始要给机器看,给机器看每一个摄像头实际上是一个测量仪器,就是怎么样能够精准的还原这个物理世界的物体,机器测量世界的依据就是颜色,在各种情况下能够精准的还原物体的各种颜色,而在各种环境下都能做到精准还原这一点非常重要。
机器需要的是测量仪,我们需要将相机和摄像头的概念转变成颜色测量仪的概念,在前端精准的测量出来再送到AI大脑进行分析和处理。其实,很多做安防的人都会问到,这个ISP怎么不行?我说不是每一家的ISP不行,是ISP这个架构不行,三、四十年前做的架构不可能适应AI时代的需求。
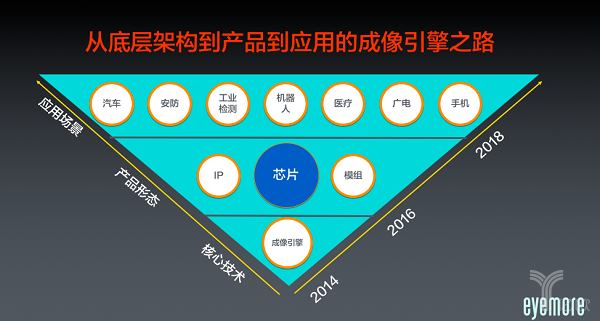
大部分的公司做产品是从应用开始做,我们是从底层开始做起。我们花了三年的时间做全新架构的成像引擎技术研发,产品较成熟之后,从今年才开始走向市场,我们把它做成芯片、模组等产品形态,会以不同的形式进行推广销售。我们也会以IP的形式,应用在安防、汽车、机器人、手机等各种相关的行业里面,所以我们是沿着从下往上走的路径,我们认为这是一个在工业行业里面解决具体问题的一种方式。
为什么这么做呢?现在大家会比较关注芯片产业,我在创业之前做过国内第一个大型的芯片电商,做了很多年芯片的市场推广,芯片的品类非常多,每个芯片都承载着一个核心技术。如果我们把每一个芯片看成一个细分市场,芯片有几千个品类,每个品类里面都是一个严格的金字塔结构,有头部也有底部,我们的目标是在视觉成像领域成为一个头部的公司,我们并不是追求有多少出货量,而是具体发挥了什么样的产业价值,我们认为在AI时代下的日企成像架构一定会被抛弃,也一定会被颠覆。
我们现在可以提供成熟的成像芯片,今年我们大概能把芯片的量产做完。同时我们可以开发工具套件,提供模组、提供IP授权,包括深度的定制。我们发现现在不管是安防还是医疗、汽车行业,很多人找我们说需要定制一个产品。定制的时候其实很有意思,很多时候也要重新做一个全新的架构,现在很多问题在于做产品的公司找人定制的时候很多地方不好定制,因为以前芯片的架构基本上不能动,所以只能在应用层面上修修补补,这是个很大的问题,所以我们现在帮很多的客户提供全栈式的定制方案。前端成像质的飞越,可以解决AI落地最后一公里
前段时间有一个科技行业的大佬找我,就说有个小设备做识别,为什么光线反光的时候不能识别?然后我们解释了半天说这个问题很难解决,很复杂,原因是什么,最后他还是问我那句话,老朱你能不能给我弄一个软件?装一装我这个反光的问题就解决了。这就反映当前一个普遍的状况,我们发现这里面做AI和做软件应用、上游技术,普遍存在着理解上的鸿沟,很多人都认为软件可以搞定一切,很多人认为AI这么强大,可以有大量的数据,一个东西哪怕前端图像再差,甚至是全黑的,我是不是可以让它通过AI大脑的方式识别出来?这个理论上来讲也不是不可行,但实际上操作的时候基本上来讲是不可行的。其实在这种图像里面核心应该就是信噪比这个概念,信噪比越高识别率越高,信噪比就是信号处理噪声,而信噪比很多时候在后端,如果这个图像一旦形成,信噪比很难再被提升。信噪比主要是在成像端提供解决方案,而后面的大脑计算端还有AI端可以做很多事情,但是对信噪比来讲非常无能为力。
还有一个就是很多人做安防设备,按照以前的习惯非常喜欢关注Sensor,所有的人都希望能把Sensor做的非常好。其实Sensor有很多的限制,它本身不能看参数,Sensor有号称120dB的,我们从来没见过产品效果。在前端Sensor是偏模拟化的产品,必须要搭在成像里。我自己选择的时候从来不相信任何Sensor的指标,只有等应用实际调完之后解决了问题,眼见为实才算。
第二个就是说动态范围的问题,其实在所有的复杂光线里,最核心的是动态范围的问题。我们安防里面比较喜欢讲星光,这个是一部分的场景,绝大部分的场景是因为动态范围不够。我们人眼的能力除了信噪比之外,眼睛不会给到大脑任何噪点的图像,我们人眼的动态范围非常宽。适应能力特别强,从暗到亮,各种各样的范围都能看得非常清楚,包括我们经常看到的各种各样的场景。其实大部分的问题在于不管你看到的现象是什么,最后都是动态范围不够导致的。我们人眼是120个dB左右,传统的ISP也不知道什么原因,直到现在都做的非常不好。以前大部分是通过视频的方式,这是我们花功夫最大的地方。我们大部分的时间、精力都聚焦在处理动态范围适应的问题,高动态范围能够保证,图像所有的细节都存在的,后端算法就不用做任何处理的东西,只是分析识别就可以了。
现在大家看到市场上的各种产品,通常来讲,大家都会用一个简单的方式来实现动态范围的调整。前端图像形成以后在后端加上一个软件合成,这些都有特别多的副作用,到了AI之后需要适应各种各样的场景。这个场景很难讲,实验室里面有简单的方式测出来,必须要通过前端在整个技术的架构上来做这件事,而动态范围影响了各种各样的东西。比如说颜色,颜色不准绝大部分来自于动态范围的问题,包括自动曝光。现在我们宽动态产品做完之后发现一个颠覆性的现象,那就是自动曝光可以取消了,宽动态足够,摄像头不需要适应光线,所有产品都是一个曝光模式,基本上能适应98%的复杂光线的场景。
动态范围我们经常容易误解的就是一张图片要看全局,不能只看局部的问题,必须同时兼顾全局和局部的处理,因为很多场景下局部的细节会比整体的更加难以处理,所以这种情况不可能说通过一个简单的后端软件,算法层面去做一个曲线来处理这个问题。我们其实花了很长的时间来解决信噪比和动态范围的问题,实际应用中这两个问题常常纠缠在一起。当我们很多时候谈到做成像,很容易犯的一个错误就是只解决眼前问题,而没有看到带来的很多副作用。
大家通常喜欢使用多帧合成来解决暗光和逆光的问题,这个副作用特别多,在AI层面基本上是不可能的。虽然在传统的安防里面有一定用处,因为传统安防场景特别固定,但到AI时代一定要适应各种各样的环境。包括前段时间有一些传统的AI芯片公司找我们对比也一样,对比完之后觉得两者差别很大,我们就一种模式且能适应各种各样的场景,而他们要不断地修改这样的模式。这就是当传统的安防升级到AI时代安防的时候,大家必须要做好准备,一定要能适应各种各样的环境,不然的话怎么叫智能?如果只能适配一个场景这就不叫智能。前端的信噪比和动态范围实际上是影响最后所有AI识别的一个最关键因素。后边的识别率可能很差,实际在后端还有空间,但是通过后端提升5%个点,在这一点上大家费的工夫非常多,其实在前端还有很多的事情可以做。专注高端应用,让机器超越人眼
对于芯片,以前都是一个单芯片解决方案,在安防里面也一样,这一点大家都很熟悉了。现在合久必分,开始有各种各样的AI芯片面世,GPU会先分出来,而处理成像复杂部分需要另外一个芯片。一个芯片变成了CPU、GPU、成像引擎三个芯片,最后这个产品的形态就由它们的组合决定。最简单的AI相机还是ISP跑一跑可以,有可能第一个加上第二个,也有可能第一个加上第三个,三个放在一起就是一个功能高端的产品。最后组合的结果决定了它的场景应用是高端还是低端,目前我们主要面向安防里面的高端应用场景,因为高端的应用场景才会要求品质,有这样的需求。什么时候从高端开始走向普及?那需要时间,之后随着时间的演进,或许三五年以后会发现还是一个单芯片能更好的解决问题,那时我们也会提供SOC,传统做IT的公司也会提供,不同的情况提出不同的解决办法。
前面讲过AI是眼睛,现在可以看到有各种各样的摄像头,我们认为未来在安防领域会出现数量庞大的AI机器。机器进化的过程是每一个AI器官都需要眼睛,从摄像头到眼睛的进化最关键的就是环境适应能力。如果摄像头能像我们的眼睛一样能适应各种各样的环境,且能够收集、识别图像的话,这个摄像头的进化就完成了。我们公司就是在做这件事情,我们觉得未来AI机器一定会比我们人眼的能力更强!这就是我们叫eyemore的意义,我们中文叫眼擎科技,意思就是超越人眼的引擎。谢谢大家!










娱乐中国2022-05-25 20:2805-25 20:28

电影界2022-05-25 20:1905-25 20:19

电影界2022-05-25 20:1505-25 20:15

电影界2022-05-25 20:1505-25 20:15

新娱在线2022-05-25 20:1005-25 20:10

南方娱乐网2022-05-25 20:0605-25 20:06

电影界2022-05-25 19:5705-25 19:57

TOM2022-05-25 18:1805-25 18:18






 点击下方菜单栏 “
点击下方菜单栏 “  ” 选择 “分享”, 把好文章分享出去!
” 选择 “分享”, 把好文章分享出去!

 为推荐给更多人
分享写下你的想法>
为推荐给更多人
分享写下你的想法>

















 京公网安备
京公网安备 网上有害信息
网上有害信息 12321垃圾信息
12321垃圾信息 北京市互联网举报
北京市互联网举报