Qzone
Qzone
 微博
微博
 微信
微信
在 KubeCon + CloudNativeCon + Open Source Summit China 2021 大会上, 英特尔®有多场技术分享,这里要给大家特别推荐的一场分享为:
Friday, December 10 • 11:20 - 11:55
深入研究:基于 CRI-RM 的中央处理器和非统一内存访问架构亲和性实现人工智能任务加速
欢迎大家来交流。
在这个议题中,演讲嘉宾将就开源项目 CRI-RM 以及它在浪潮 AIStation 的实际应用跟大家分享。
CRI-RM(Container Runtime Interface, Resource manager), 是英特尔®初创的一个开源项目,其目的是通过在节点上的动态划分系统资源,配合 Kubernetes 调度器,实现在节点层面上的最优任务编排,把 Intel® 平台的特性完美的适配到 Kubernetes 的集群环境里。
AIStation 是浪潮发布的人工智能开发平台,面向深度学习开发训练场景,全面整合 AI 计算资源、训练数据资源以及 AI 开发工具。
随着 AI 技术创新、场景化 AI 应用持续落地,越来越多的企业开始尝试搭建 AI 平台,进行 AI 技术开发、模型训练,并将其应用到业务流程之中。但是,AI 平台的搭建并非一蹴而就。从 AI 模型的开发,到最终进入到生产部署阶段,企业将面临资源管理、模型测试等带来的不同挑战,同时还需要能够充分发挥 CPU 等硬件的性能潜力,提升 AI 训练性能。
浪潮与英特尔合作,利用基于容器运行时接口的资源管理器 CRI-RM 进行了 AI 训练加速实践,可以在 K8s 集群上,按照拓扑资源实现物理主机的最优分配,从而突破使用 K8s 原生 CPU 管理机制所带来的性能瓶颈,大幅提升 AI 计算的性能。
AI 模型训练进入云原生时代,算力挑战浮出水面,提到 AI 模型训练,不少开发者脑海中浮现出的是繁琐的资源申请与管理流程、巨大的算力消耗、漫长的模型训练时间……而云原生技术的出现,能够在很大程度上化解 AI 资源的调度难题。通过 K8s ,企业将能够管理云平台中多个主机上的容器化应用,实现 AI 资源的统一部署、规划、更新和维护,能够有效提高用户的 AI 资源管理率,提升平台的可管理性、可扩展性、弹性与可用性。
浪潮 AIStation 应运而生。面向人工智能企业训练开发与服务部署场景,浪潮 AIStation包含完整的模型开发、训练和部署全流程,可视化开发、集中化管理等特性,能够为用户提供高性能的 AI 计算资源,实现高效的计算力支撑、精准的资源管理和调度、敏捷的数据整合及加速、流程化的 AI 场景及业务整合。
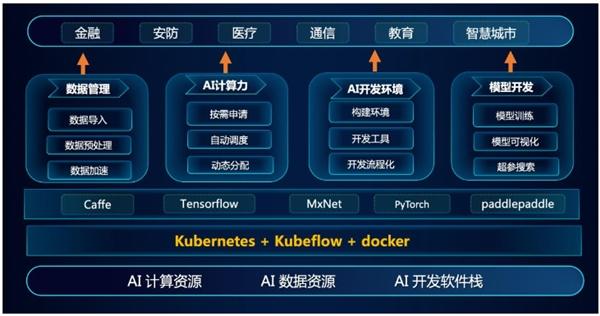
图:浪潮 AIStation V3 架构图
要通过 AIStation 构建 AI 应用平台,需要进行的一个重要抉择便是:算力如何提供?虽然GPU 被普遍用于 AI 训练,但这并不意味着 GPU 是唯一选择。事实上,在大量的行业场景中,用户希望充分利用既有的 CPU 计算资源,灵活地满足 AI 等多种负载的要求,同时减少资本支出。 但是,在 K8s 集群上使用 CPU 进行训练,用户会遇到一定的性能瓶颈。这是因为 K8s 原生的 CPU 管理机制没有考虑 CPU 绑定与 NUMA 亲和性,高版本的 K8s 只会对 QOS 为 Guaranteed 的 Pod 生效,这可能会导致 CPU 在 AI 训练中无法充分发挥性能。
CRI-RM 优化助力浪潮 AIStation 突破性能瓶颈,在发现 K8s 集群上的 AI 算力瓶颈之后,浪潮与英特尔展开了深入合作,使用 CRI-RM(基于容器运行时接口的资源管理器)技术对 K8s 进行了优化。该组件可以插在 Kubelet 和 Container Runtime(CR) 之间,截取来自 Kubelet CRI 协议的请求,扮演 CR 的非透明代理,跟踪所有集群节点容器状态,能够更好地将处理器、内存、IO 外设和内存控制器等资源分配给应用负载,从而有效提升性能表现。
在TensorFlow CNN测试用例中,这一优化被证明能够实现高达 57.76% 的性能提升[1]。这意味着在未对硬件配置进行更新的前提下,CRI-RM 的应用会带来大幅度的性能提升,使得用户无需在进行硬件投入便能够获得可观的 AI 训练性能提升,从而提高基础设施的利用效率,并节约总体拥有成本 (TCO)。
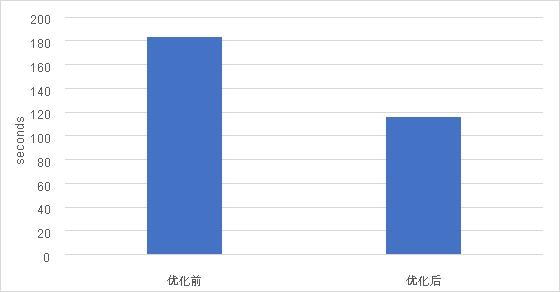
图:使用 CRI-RM 进行优化前后的性能对比
(Tensorflow | model: customized cnn,越低越好)
在此次优化的基础上,浪潮与英特尔还在探索在基于第三代英特尔® 至强® 可扩展处理器的 HPC 集群上进行进一步的性能验证,并计划在利用 CPU 进行人工智能推理和训练方面进行更为广泛的合作,通过硬件选型、软件优化、系统集成等多种不同的方式,加速从云端到边缘基础设施上的人工智能性能表现。
查看完整方案文,请访问此方案
[1] 数据援引自浪潮内部测试结果;测试配置:英特尔至强金牌6132处理器 @ 2.60GHz,28 核,56 线程,192GB内存,Centos 7.8.2003,Kubernetes 1.14.8,Docker 19.03,AIStation 3.1

KubeCon + CloudNativeCon + Open Source Summit China 2021 由云原生计算基金会 CNCF 主办。作为云原生领域的顶级技术盛会,历年的 KubeCon + CloudNativeCon + Open Source Summit China 都汇聚了国内外最活跃的开源云原生社区、最先进的技术代表与行业的最佳落地实践,推动云原生计算领域的知识更新和技术进步。本届大会的议程安排现已全面上线,更多详情请查看大会官网。





TOM2026-01-15 17:2001-15 17:20






 点击下方菜单栏 “
点击下方菜单栏 “  ” 选择 “分享”, 把好文章分享出去!
” 选择 “分享”, 把好文章分享出去!

 为推荐给更多人
分享写下你的想法>
为推荐给更多人
分享写下你的想法>