Qzone
Qzone
 微博
微博
 微信
微信
8月9日壁仞科技的首颗GPU芯片发布之际,发布会上播放的宣传片还真是能让人联想起英伟达“IamAI”的那则著名视频。而壁仞科技选择的这条赛道,和大部分做AI芯片的国内厂商都不大一样:其GPU芯片、板卡和系统是要和英伟达正面硬碰硬,用于云上大规模的AI训练与推理,以及HPC的。
壁仞科技创始人、董事长、CEO张文说从最初走访20家客户的反馈来看,大家都想要一款“国产大算力芯片”。虽说“做通用GPU芯片,99%都做不下去”,但“我思考,周期长、壁垒高、投入大,换句话说就是资本密集、人才密集和资源密集的需求。这三点恰好都是我的长项。”于是在成功说服投资人以后,壁仞就开启了这一征程。
壁仞科技成立于2019年9月,用张文的话来说“三年时间,发展到千人团队、芯片从PPT到量产”是个奇迹。今年3月底就有壁仞BR100芯片成功点亮的消息,“全球通用GPU算力记录,第一次由中国企业创造。”张文说,“中国通用GPU芯片,第一次进入每秒1千万亿次的计算新时代。”
而从壁仞科技的宣传片来看,其GPU芯片要覆盖“从微观细胞到浩瀚宇宙,从坚实的道路到虚拟的空间”,从生物科学、工业设计、生产制造,到农业耕作、航天航海、地质勘探与宇宙探索。大约算是与英伟达的全方位市场重合了。要做到这些可真的不容易,也绝不仅仅是算力堆砌所能轻易达成的。本文我们就详细谈谈壁仞科技本次发布的1个架构、2颗芯片(及对应的OAMmodule与PCIe板卡)、1台服务器,以及对应于生态建设的软件栈。

两颗芯片:BR100与BR104
这次壁仞科技发布了两颗芯片:BR100和BR104。这两者的区别主要在于BR100是两片相同的die(或chiplet)封装到一起;BR104则只用了1片die,所以相关算力与IO等参数大多为前者的一半,适配不同的市场需求。
所以我们将注意力主要放在BR100身上。从一些关键数据就可以看出本次发布的BR100GPU是真正的“大”芯片。壁仞在宣传中提到“创下全球(通用GPU芯片的)算力记录”“单芯片算力达到PFLOPS级别”“峰值算力是国际厂商在售旗舰产品3倍以上”。
从制造和封装技术的堆料来看,应该更能体会其规模,包括7nm工艺、“770亿个晶体管”,以及张文提到的“1000mm²”左右的diesize。这个diesize数字当然也就突破了光刻机所能处理的reticlelimit,所以是将两片die封装到一起。

从壁仞科技联合创始人、CTO洪洲的介绍来看,BR100明确采用了台积电的2.5D CoWoS-S封装方案——两片die和周边HBM2e内存都放在一片硅中介(silicon interposer)上。我们在刚刚发布的《先进封装的现在和将来》一文中详细介绍过这种先进封装技术,国内厂商在用的应当还寥寥无几。
而且dietodie互连采用超高速112GPAM4SerDes,die间通讯带宽达到了896GB/s——这个速度可一点也不比某“国际大厂”发布没多久的GraceHopperSuperchip的NVLink-C2C差。
基于以上数字,推荐感兴趣的同学去比一比,以及Intel Ponte VecchioGPU,在die size、晶体管数量和先进封装技术的应用上都有一定的可比性;也能更进一步地体会壁仞BR100大约是怎样的定位。
实际上,英伟达在今年GTC上发布、尚未上市的Hopper架构的GH100diesize为814mm²,800亿个晶体管。“大芯片”之间过招,在堆料上真的已经到了白热化程度。

BR100的理论算力水平如上图所示,不同格式与精度的算力值,对应于BR100在训练和推理方面的适用性。壁仞提到的“全球算力记录”和突破PFLOPS,应该就是指BF16格式(1024TFLOPS)。
这里有个TF32+,是壁仞新推的一种数据格式,后文将会提到。在AI训练中相对关键的BF16、TF32/TF32+峰值理论算力,都有着很漂亮的水平;着力推理的Int8也达到了2048TOPS。
其他配置数据还包括2.5D封装在一起的64GBHBM2e内存,“超300MB片上缓存”,2.3TB/s外部I/O带宽,64路高清编码、512路高清解码加速。

对比“国际厂商在售旗舰”的峰值算力数据——这很显然比的就是Ampere架构的A100;AI计算相关主要数据格式的差异还是实打实的(FP32的数据,属于欺负A100的算力侧重点了;而且A100堆的FP64算力在HPC领域也是很重要的)。
据说在“开发者云上的实测算力”,BR100的数据还更好看一些。有兴趣的同学还可以拿尚未发售的英伟达Hopper新架构来比一比,虽然这种峰值算力对比的意义并不算特别大。另外要考虑对比双方的芯片产品大规模铺货的时间。

到更为真实的负载中,跑主流、具代表性的网络,包括CV、NLP,还有现在很流行的Transformer,壁仞BR100仍然是有不小的优势的,“平均加速比2.6x”。不过这种涉及到实际业务的对比,不仅是芯片本身,还要带上系统、软件的对比,应当进一步明确对比对象和内容。我们很期待未来看到壁仞BR100及对应系统参与MLPerf基准测试。
实则从这些与竞品的性能对比数据,是能够发现壁仞研发团队的前瞻性的。这家公司2019年定义BR100芯片,到如今产品发布历经3年时间,AI与通用计算加速市场环境变化不小。首次做芯片,就要预见未来3年的算力增长,并在对应时间节点把产品拿出来,既有风险又有难度。
另外,单die的BR104主要配置与参数如下图所示。据说即便是单die的BR104,相比于“国际厂商在售旗舰”仍然有着1.4-1.6倍的算力优势,包括上述不同数据格式,与主流模型基准测试性能比较。

有关芯片架构、特性、存储子系统、IO互连的部分此处还尚未提到;比如说主机接口PCIeGen5,也特别支持了CXL互连协议;还有壁仞自研的BLink点对点全互连技术能将8个GPU有效连接在一起等等。我们将这部分放到本文的最后。
芯片构成模组、板卡和服务器以后
更往上的板级系统层面,BR100、BR104芯片当然是需要对应到具体的产品形态的。这次壁仞发布了两款具体的硬件产品:壁砺100和壁砺104,分别应用了BR100和BR104芯片,这两款产品分别以OAM(OCPAcceleratorModule)模组与PCIe板卡的形态存在。算力规格之外,功耗分别对应550W和300W。


壁仞科技联合创始人、总裁徐凌杰特别提到,其中壁砺100“在板级和系统层面做了非常多的创新”。供电方面,“我们专门为这套系统打造了48V电源,有着超高的电源密度和开关频率,提供稳定的供电和超高的电源效率。”
而在散热方面,“我们在板卡上采用快速均温技术,增加了热腔体积和撞风面积,有效提升了散热效率。”徐凌杰表示,“我们还优化了散热器的外形,能够在不影响散热的前提下降低5%以上的风阻。”除此之外,“考虑到系统的稳定性和可靠性,我们也设计了一套专门的中断和保护机制。”右图的热力图表现的是OAM模组之上温度的分布情况。

系统和性能扩展相关的部分,应该也是很多人关注的重点。“我们把8个OAM模组放在通用UBB主板上,形成8卡之间点对点的全互连拓扑。充分利用BR100上面的高速接口,和UBB的互连基础设施,8张卡之间两两互连。”徐凌杰说,“节点内每张卡能够有448GB/s的互连带宽,节点之外还有64GB的带宽。”8卡对分带宽1.8TB/s。
这是“国内芯片设计厂商中,第一个实现在OAM系统中,单节点8卡的全互连拓扑”。全互连拓扑的价值,自然就在于专线通信,每张卡在系统中完全对称,便于分布式调度和部署。

PCIe板卡形态的壁砺104则能够部署在大部分2-4U的服务器里。徐凌杰特别提到,壁砺104也能够实现多卡之间的高速互连。“我们为此专门设计了高速的桥片,能够在4张卡之间形成点对点的全互连拓扑,带宽192GB/s。”

值得一提的是,本次发布会上壁仞特别宣布了与浪潮合作推出的OAM服务器:海玄。这台服务器的理论峰值算力(BF16)达到8PFLOPS;512GBHBM2e内存;支持PCIe5.0和CXL;1.8TB/s对分互连带宽;最大功耗7kW。
这个部分的最后,有必要说一说AI芯片与GPU厂商于系统层面的常规对比项目:少不了要和“国际厂商”对比TCO(总拥有成本)和功耗。这是真正涉及到性价比和效率的部分。
徐凌杰表示,“用国际巨头在售的旗舰产品,6000台服务器(DGXA100640GB?)可以达到15EFLOPS的浮点算力,需要3000台机柜,占地空间1万平方米以上,峰值功耗39兆瓦,最高需要3.4亿度电每年,相当于4.2万吨煤的发电量。”

而如果换成OAM服务器海玄,“只需要2000台海玄服务器,达到16EFLOPS的算力;只需要1000个机柜,占地面积不超过3500平方米,峰值功耗14兆瓦,1.2亿度年用电量,相当于1.5万吨标准煤发电量,实现了整体方案64%的成本下降。”
当然这是个理想数据,我们在不少AI芯片供应商那里都看到过类似的对比;实际情况很大程度还是受到业务类型、开发生态、软件和系统效率等各方面的因素影响。目前壁砺104PCIe板卡已经向部分用户“开放邀测”,而海玄OAM服务器则“正在内部进行紧锣密鼓的测试,即将在下个季度与客户见面”。
软件与生态建设情况
洪洲在介绍芯片架构之前就提到,壁仞科技要“占领数字经济的制高点”。“我们计划通过我们的芯片、计算卡,要承载我们的软件来对接应用。刚开始兼容主流生态,然后抢占整个生态的话语权”。“我们关键是要打造生态,真正将生态打好才是立足之本。”
要在现如今的通用计算GPU市场有所发展,芯片做得再好,没有庞大的生态都将难以生存。而且生态一直也是英伟达赖以生存与业绩数年持续蹿升的根源所在。英伟达当前所涉足的通用计算加速领域,每年GTC上新发布的加速库、框架、软件和应用,都足以让竞争对手汗颜——甚至是一些细分、小众的领域。
尤其是每年更新个什么库,相同硬件的效率就提升1倍,有时都足以将DSA架构芯片的效率领先优势吃干抹净。更不用谈上层应用面向开发者时,易用性有时可以将竞争对手甩开几条街。
壁仞科技作为一家刚刚发布第一颗芯片、成立才3年的新入局者,自然不大可能做到一蹴而就。我们此前采访不少生态投入时间超过5年的AI芯片企业,他们都对英伟达的生态建设水平感到无奈。这预计也将成为壁仞科技接下来很长一段时间内要投入大量人力物力的部分。
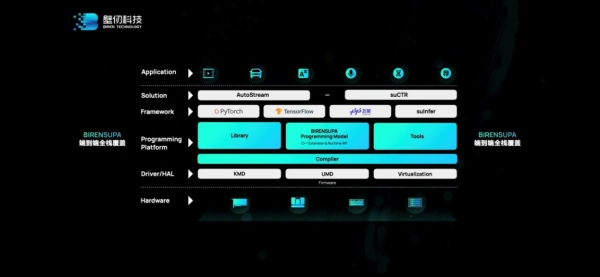
上面这张图是壁仞的BIRENSUPA(以下简称SUPA)软件全栈,从驱动、硬件抽象层、编程平台、框架,到具体的解决方案和应用。除了相关壁仞GPU自身架构特性的一些接口(下文架构介绍中也会有涉及),这里比较值得一提的包括框架层支持PyTorch、TensorFlow,和已经在合作中的百度飞桨PaddlePaddle——百度也出现在发布会上,给出了“产品兼容性证明”;框架层有个壁仞自研的推理引擎suInfer。
上层的解决方案,现阶段主要有两个:AutoStream和suCTR。壁仞科技联席CEO李新荣介绍说,AutoStream智能视频分析引擎是基于GStreamer框架开发的软件库,用于端到端的智能分析。“它可以对图像以及视频的数据做前端和后端的处理,充分利用壁仞GPU的解码能力和推理加速能力,高效地支持视频分析应用。”未来还会有更多AutoStream的功能问世。
而suCTR是个广告推荐训练框架,“支持基于GPU架构的训练框架,用在广告推荐场景上;采用多级稀疏参数存储架构,单机就可以支持TB级参数,并且可以通过多级扩展来支持更多的大规模参数;兼容TensorFlow,减少用户开发的迁移成本。”
开发者比较关心的部分具体内容可见以下PPT;就一家刚刚发布芯片的企业而言,我们认为这样的生态构建水平已经是比较优秀的了:



另外作为生态建设的一环,壁仞科技“开发者云”当前已经上线。壁仞也现场演示了开发者云的使用。“开发者云是基于壁仞suCloud机器学习平台搭建的集成式开发环境,旨在为开发者提供可远程访问壁仞GPU资源的云端入口。”
生态建设前期,壁仞似乎和不少高校展开了合作,主要着力在和高校建立合作关系,从学术研究、人才培养和科研成果转换上入手。从壁仞展示的视频来看,目前涉及的合作方向包括医疗影像、分子动力学、电磁仿真等领域。虽然不清楚合作深度和成果产出如何,但这本身就是生态扩展、为未来打基础的长远方案。
“壁立仞”芯片架构
感觉能在发布会上从高抽象层级谈技术的企业,在国内还真是稀缺。壁仞在这次发布会上,花了比较多的篇幅着墨于自家GPU芯片的“壁立仞”架构。做大算力可不是堆晶体管就行的,这其中涉及到PPA权衡、内存功耗限制问题、兼容性等等。本文最后,我们就来谈一谈构成BR100/BR104芯片的壁立仞架构,有何独特之处。
洪洲给出了壁立仞架构的6大特性:TF32+数据格式支持、TDA张量数据存取加速器、C-Warp协作开发模式、NME近存储计算引擎、NUMA/UMA访存机制、SVI安全虚拟实例。虽然听起来其中的某些还是比较通用。

这是BR100逻辑框架图,其上包含有计算单元、2Dmesh片上网、HBM2e存储系统、媒体引擎、连接主机的PCIeGen5接口、互连接口。

放大计算核部分,这是流处理器簇(SPC),采用标准化的模块化设计,上面能跑4096并行线程。一个SPC内部包含有16个EU(执行单元),每4个EU可配置成1个CU(计算单元)。一个BR100内部有32个这样的SPC流媒体簇。

放大其中的EU。一个EU主要包含两部分,一部分是“通用流式处理器(V-core)”。“我们采用了SIMT通用并行处理器”,BR100的“通用性主要就来自这个处理器,它支持各种各样的指令,而且是完全并行的通用架构”。这部分应该也是能够兼容CUDA的原因。
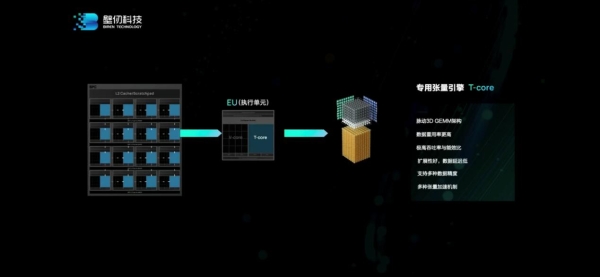
另一个部分就是tensorcore。“我们的做法和业界不大一样。我们的tensor核是完全集成在向量核里面的,作为向量核的加速器。”洪洲说,“其优点在于,可以把16个tensor核连在一起,达成更大的tensor核,让矩阵运算效率得到极大提高。我们算下来大概能提高30%。”
“矩阵运算是AI、HPC里面最重要的运算。所以这个设计至关重要。这样的设计能提高能效比,让数据重用性变得更好。”
“我觉得到底用通用架构还是DSA架构,这个争论是没有意义的。”洪洲谈到,“BR100里面,这两者都有了,既有通用性,也有很好的PPA。”

分布式共享L2cache也是洪洲特别提到的创新点。“传统GPU的L2cache一般在芯片中间,或者芯片边上,在memorycontroller旁边。我们的设计是分布式缓存,和每个大的计算核在一起,也能够共享,通过片上网将其连在一起。”“这样的好处是,让数据和计算单元挨得很近,与此同时又在芯片level做共享。”
基于以上信息,BR100芯片同时能跑128000个线程,总计8192个通用流式处理器、512个张量加速器,256MB分布式共享缓存。

BR100所用的片上网络(NoC),为“网格式多播(multicast)片上互连”。“权重一般来说是可以共享多播的;当你跑模型并行,trainingsample也可以共享多播。这样就能极大减少对内存的带宽压力,减少片上网link的带宽压力。”
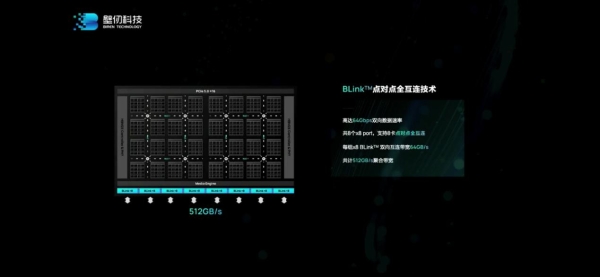
IO方面值得一提的特性,除了PCIeGen5主机接口支持——128GB/s带宽,并且支持CXL互连协议以外;BLink点对点全互连技术,在壁仞科技的版图中应该也是很重要的——可类比于英伟达的NVLink。
“我们有8组BLink接口,其中7个接口可以连接另外7个GPU,最终将8个GPU有效连在一起。”洪洲说,“我们为什么要自研这个接口?因为它能够给我们更好的控制。通过这项技术,把8个GPU当成1个GPU来用,并且把数据多播、计算核之间同步都通过接口来实现。”

6大亮点中的第一个就是TF32+数据格式的支持。“两年前,头部厂商引入了TF32,这个格式能够让网络比较容易收敛。但我们和客户交流的时候发现,这还远远不够。很多客户在某些场景下,为了0.1%的精度提高,宁愿速度跑慢一点,或者加更多设备。”
“我们的TF32+,精度bit有15bit(E8M15),TF32就只有10bit。我们增加了5bit,相当于增加了32倍精度。”洪洲说,“即使这样,我们的TF32+算力仍然是头部厂家TF32的3.3倍。”所以最终达成了“更高的精度”和“更大的算力”。

架构层面的另一个亮点在于TDA(TensorDataAccelerator)张量数据存取加速器。这个加速器用于offload计算单元(SPC)的数据存取工作。“它是个专门的加速器,像数据的加压、解压、地址计算、同步。它能让计算和数据搬动做到异步。”
实际上,以下多项特性都着力于减少数据通讯产生的开销——在AI计算时代,这个命题正被不断放大。而“高算力”架构现在总是要花大量的精力在应对存储墙的问题上。包括C-Warp协作并发、NME近存储计算引擎、NUMA/UMA访存机制:


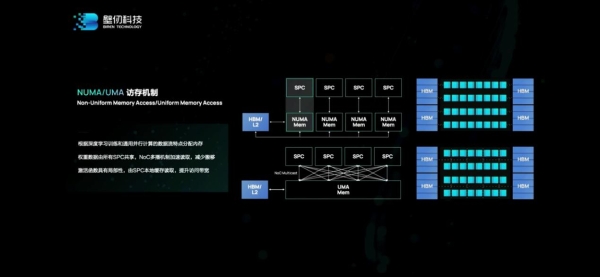
比如C-Warp协作并发相比于传统GPU的warp和warp之间不能直接通讯(需要经由cache来交换数据),“我们这种模式可以藉由一些同步方式,通过RegisterFile来直接传递数据,也就减少了数据的搬移。”
而NME近存计算引擎应当和前面提到的分布式L2cache也有关,“让计算发生在数据呆着的地方。数据走到哪儿,计算就应该在哪儿发生。”这里的“reductionengine”大约是关窍所在。NUMA/UMA访存机制也是考量不同数据特性,减少数据通讯的距离和次数。
洪洲说由于数据存取需要大量开销,很多冯诺依曼体系架构的芯片,功耗真正花在“算”的部分就只有10%。“我们很骄傲地说,BR100测下来,大部分功耗都是花在了‘算‘上面。基于不同的场景,有些场景能到70%,有些60%,这已经非常好了。这是对计算模式的颠覆。”以上所有技术在此应当都是至关重要的。

虚拟化和安全相关的技术,对当代数据中心GPU而言自然也不能少。SVI安全虚拟实例特性的一个亮点,应该是支持1、2、4、8份实例的“物理切分”。“每个物理切分,memory、缓存、计算单元、片上网的link都是私有的,和旁边在跑的东西完全隔离,相互不会有影响。”
另外还有国密1级安全标准支持等特性,以及性能方面BR100“即使切成8份,每份算力也有256TOPS(INT8),是现在主流推理卡的2倍性能”等。

这是个很好的起点
壁仞BR100/BR104芯片,以及软件生态、OAM模组与PCIe板卡的发布还是相当振奋人心的。至少从这次的发布会来看,3年时间交出的答卷让人满意。无论是芯片算力水平、架构亮点、所用的制造和封装技术,还是系统产品的能效、TCO。而且如前所述,壁砺104很快就要量产出货了,海玄OAM服务器今年Q4也将开放邀测。
不过GPU通用计算和AI市场的竞争也实在不简单,要在既有市场参与者占据统领地位的环境中占得一席之地,甚至“抢占生态话语权”都绝非短时间内可以达成。实际上,英伟达当前的优势,一方面来自xPU芯片和系统的覆盖,不仅是GPU芯片和系统,还体现在networking等领域的不断开花结果。而老生常谈的软件生态,更是全栈自下而上的覆盖,以及持续不断的行业横向扩张。
无论如何壁仞BR100的发布都是个出色的开端,接下来等待壁仞科技的还会有更多的挑战。产品落地和持续的生态建设会是所有人都将密切关注的。











TOM2025-06-10 18:0106-10 18:01






 点击下方菜单栏 “
点击下方菜单栏 “  ” 选择 “分享”, 把好文章分享出去!
” 选择 “分享”, 把好文章分享出去!

 为推荐给更多人
分享写下你的想法>
为推荐给更多人
分享写下你的想法>