Qzone
Qzone
 微博
微博
 微信
微信
10月24日,趣丸科技宣布与香港中文大学(深圳)联合研发的语音大模型“MaskGCT”正式在Amphion系统中开源,面向全球用户开放使用。区别于传统TTS模型,该模型采用掩码生成模型与语音表征解耦编码的创新范式,在声音克隆、跨语种合成、语音控制等任务中展现出卓越效果。

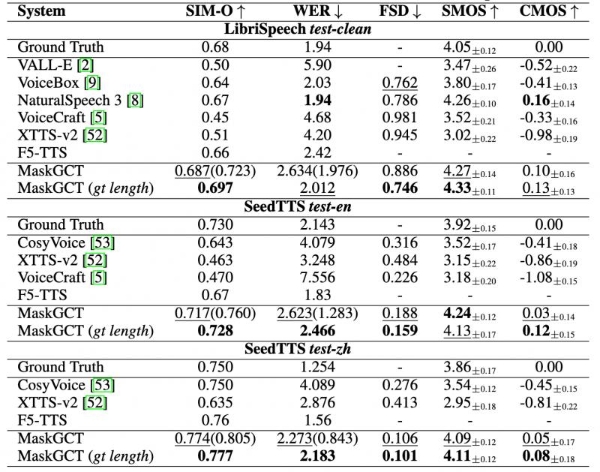
据介绍,MaskGCT在三个TTS基准数据集上都达到了SOTA效果,超过当前最先进的同类模型。
模型能力全球领先,跻身第一梯队
相较于现有的TTS大模型,MaskGCT在语音的相似度、质量和稳定性上进一步突破,尤其在语音相似度方面处于绝对领先地位。显著特点如下:
1、秒级超逼真的声音克隆:提供3秒音频样本即可复刻人类、动漫、“耳边细语”等任意音色,且能完整复刻语调、风格和情感。
2、更精细可控的语音生成:可灵活调整生成语音的长度、语速和情绪,支持通过编辑文本编辑语音,并保持韵律、音色等方面的极度一致。
3、高质量多语种语音数据集:训练于香港中文大学(深圳)和趣丸科技等机构联合推出的10万小时数据集Emilia,是全球最大且最为多样的高质量多语种语音数据集之一,精通中英日韩法德6种语言的跨语种合成。
优秀的模型离不开顶尖的团队。MaskGCT研发团队在语音领域拥有深厚的研究积累和原创性成果。该工作由港中大(深圳)-趣丸科技人工智能联合实验室成员完成,这主要依托趣丸科技十年深耕音频技术领域和亿级高质量语音用户的服务经验,以及香港中文大学(深圳)国际一流水平的师资队伍。
技术范式创新,突破大模型能力边界
MaskGCT(Masked Generative Codec Transformer)是一个大规模的零样本TTS模型,采用非自回归掩码生成Transformer,无需文本与语音的对齐监督和音素级持续时间预测。其技术突破性在于采用掩码生成模型与语音表征解耦编码的创新范式。实验表明,MaskGCT在语音质量、相似度和可理解性方面优于当前最先进的TTS模型,并且在模型规模和训练数据量增加时表现更佳,同时能够控制生成语音的总时长。MaskGCT已在香港中文大学(深圳)与上海人工智能实验室联合开发的开源系统Amphion发布。

据介绍,MaskGCT是一个两阶段模型。在第一阶段,模型使用文本预测从语音自监督学习(SSL)模型中提取的语义标记;在第二阶段,模型基于这些语义标记预测声学标记。MaskGCT遵循掩码预测学习范式。在训练过程中,MaskGCT学习根据给定的条件和提示预测掩码的语义或声学标记。在推理过程中,模型以并行方式生成指定长度的标记。通过对10万小时的自然语音进行实验,结果表明MaskGCT在质量、相似度和可理解性方面优于当前最先进的零样本TTS系统。
科研成果走出实验室,应用前景广阔
MaskGCT的诞生,再次证明即使在算力受限的情况下,中国AI企业仍有勇气和底气追赶并超越西方同行。
然而,除了保持技术领先,大模型的更大价值在于走出实验室,赋能千行百业惠及千家万户,成为驱动经济增长的新质生产力。
目前,MaskGCT在短剧出海、数字人、智能助手、有声读物、辅助教育等领域拥有丰富的应用场景。为了加快落地应用,在安全合规下,趣丸科技打造了多语种速译智能视听平台“趣丸千音”。一键上传视频即可快速翻译成多语种版本,并实现字幕修复与翻译、语音翻译、唇音同步等功能。该产品进一步革新视频翻译制作流程,大幅降低过往昂贵的人工翻译成本和冗长的制作周期,成为影视、游戏、短剧等内容出海的理想选择平台。
《2024年短剧出海白皮书》显示,2023年海外市场规模高达650亿美元,约为国内市场的12倍,短剧出海成为蓝海新赛道。以“趣丸千音”为代表的产品的出现,将加速国产短剧“走出去”,进一步推动中华文化在全球不同语境下的传播。










 点击下方菜单栏 “
点击下方菜单栏 “  ” 选择 “分享”, 把好文章分享出去!
” 选择 “分享”, 把好文章分享出去!

 为推荐给更多人
分享写下你的想法>
为推荐给更多人
分享写下你的想法>