




 Qzone
Qzone
 微博
微博
 微信
微信
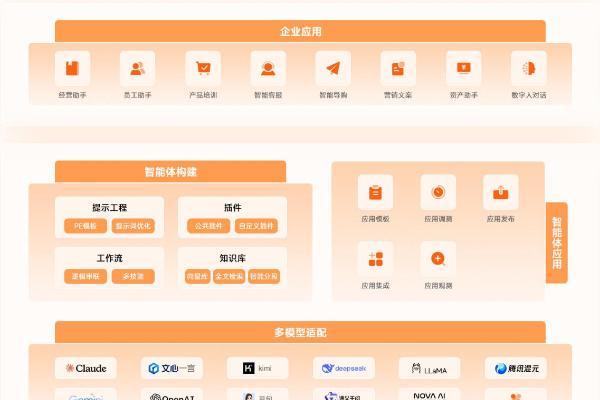
随着人工智能技术的迅猛发展,众多企业正加速构建内部知识库,旨在利用人工智能的强大动力,进一步巩固并提升企业竞争优势。作为芯片、器件、模组及板级解决方案的杰出供应商,某知名半导体企业不仅在无线通信、安防监控、智能家居等领域推出了众多高性能芯片产品,还在积极探索如何更好地构建一个深度融合软硬件的专业知识库。
在此过程中,该企业面临了一个重大挑战:将海量PDF文档资源——包括论文、硬件产品手册、内部代码等专业资料——高效转化为Markdown格式的挑战。Markdown格式因其简洁直观、易于阅读与转换的特性,成为了构建知识库的理想语料输入形式。
然而,PDF文档向Markdown格式的转换并非易事,它要求精确解析并导出文档中的标题、段落、列表、表格及图片等复杂元素,这是一项既繁琐又耗时的工作,具体需要实现以下几个关键功能:
PDF结构化解析:需要准确识别和提取PDF中的标题、段落、列表、表格等信息,并将其转换为Markdown格式。
文本识别与处理:针对企业内部历史资料中存在的小图标(如警告、信息、危险、须知等)进行文本识别,确保程序能准确定位并理解当前内容信息。对于部分无法直接获取文本的图片文档,提供整页OCR功能,确保文本信息的全面提取。
深度解析和渲染:需要深度解析PDF中的基本元素,包括文本、图形、图像等,并针对复杂的PDF布局结构,提供自定义辅助解析工具,以确保信息的完整性和准确性。此外,还需支持按用户指定的分辨率对PDF的部分区域进行渲染,并兼容多种位图格式和图片保存格式,满足多样化的需求。
为应对上述挑战,某知名半导体企业选择了福昕PDF SDK作为其技术合作伙伴。福昕PDF SDK凭借卓越的版式识别技术和全面的PDF解析接口,提供了以下技术支持:
1、通过版面识别技术,对文档进行结构化数据提取,包括表格、标题、列表等信息。开发者可以根据自己关注的结构进行筛选和过滤出想要的内容。
2、其先进的OCR功能支持识别各种尺寸的图片,包括小的图标,以及扫描件文档,并能处理数十种语言的混合识别。该功能不仅能还原PDF中原始的文本字体、字号位置等信息,还支持生成双层PDF和可编辑的PDF文档,极大提升了文档的可用性。
3、借助PDF内容解析功能,开发者可以轻松获取PDF文档的所有内容数据,并根据原始数据进行自定义逻辑处理。同时,该SDK还支持对PDF中的图形元素进行高保真渲染和输出,确保转换出的Markdown文档在视觉和格式上与原始文档保持一致。
通过福昕PDF SDK的强大功能,某知名半导体企业成功实现了海量PDF文档资源向Markdown格式的高效转化。这一转变不仅显著提升了工作效率,还大幅提高了文档管理的质量。如今,该企业的知识库建设更加系统化和专业化,为其内部协作和技术创新提供了坚实的技术保障。
















 点击下方菜单栏 “
点击下方菜单栏 “  ” 选择 “分享”, 把好文章分享出去!
” 选择 “分享”, 把好文章分享出去!

 为推荐给更多人
分享写下你的想法>
为推荐给更多人
分享写下你的想法>






























