Qzone
Qzone
 微博
微博
 微信
微信
前言
随着云、云原生的发展,越来越多的客户意识到了“数据”的重要性,纷纷掀起了一波数据累积浪潮。
现今,国内外都有大量的数据采集器,但大多数采集能力单一,比如 Telegraf 仅支持指标,Filebeat只服务日志,OpenTelemetry 的 Collector对非云原生的组件并不友好,需要大量安装 Exporter插件。为了实现系统的可观测性,需要使用多个采集器,造成资源浪费。
Datakit 是目前唯一的真正一体化实现各种环境(传统环境,云/云原生)统一数据采集平台,一个进程或 Daemonset Pod就可以实现全方位的数据采集,配置体验良好,开源且可扩展性强。本文将全面介绍 Datakit 相关功能。
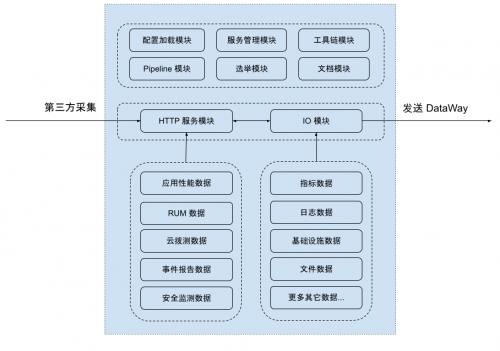
(DataKit 内部架构)
多维度可观测性数据采集
Datakit 支持从各种基础设施、技术栈中采集 Metrics、Logs、Traces 等数据,并对这些数据进行结构化处理。
1、实时基础设施对象
DataKit 支持从主机,容器,k8s,进程,云产品,所有基础设施对象实时状态一网打尽。例如:
(1)Datakit hostobject 用于收集主机基本信息,如硬件型号、基础资源消耗等。
(2)进程采集器可以对系统中各种运行的进程进行实施监控, 获取、分析进程运行时各项指标,包括内存使用率、占用CPU时间、进程当前状态、进程监听的端口等,并根据进程运行时的各项指标信息,用户可以在观测云中配置相关告警,使用户了解进程的状态,在进程发生故障时,可以及时对发生故障的进程进行维护。
2、指标
相比 Telegraf 只能采集时序数据,DataKit 涵盖更为全面的数据采集类型,有海量的技术栈的指标收集能力,采集器的配置更简单,数据质量更好。
3、日志
日志数据对于整体的可观测性,其提供了足够灵活、多变的的信息组合方式,正因如此,相比指标和 Tracing,日志的采集、处理方式方案更多,以适应不同环境、架构以及技术栈的采集场景。
从磁盘文件获取日志
这是最原始的日志处理方式,不管是对开发者而言,还是传统的日志收集方案而言,日志最开始一般都是直接写到磁盘文件的,写到磁盘文件的日志有如下几个特点:
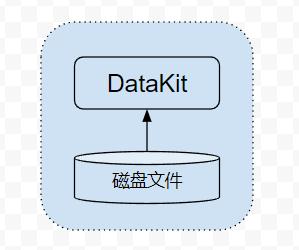
(1)序列式写入:一般的日志框架,都能保证磁盘文件中的日志,保持时间的序列性
自动切片:由于磁盘日志文件都是物理递增的,为避免日志将磁盘打爆,一般日志框架都会自动做切割,或者通过一些外部常驻脚本来实现日志切割
(2)基于以上特征,DataKit 只需要要持续盯住这些文件的变更即可(即采集最新的更新),一旦有日志写入,则 DataKit 就能采集到,而且其部署也很简单,只需要在日志采集器的 conf 中填写要采集的文件路径(或通配路径)即可。
通过调用环境 API 获取日志
这种采集方式目前主要针对容器环境中的 stdout 日志,这种日志要求运行在容器(或 Kubernetes Pod)中的应用将日志输出到 stdout,然后通过 Docker 的日志接口,将对应 stdout 上的日志同步到 DataKit。
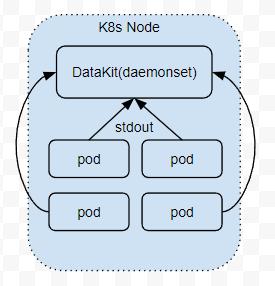
远程推送日志给 DataKit
对远程日志推送而言,其主要是
(1)开发者直接将应用日志推送到 DataKit 指定的服务上,比如 Java 的 log4j 以及 Python 原生的 SocketHandler 均支持将日志发送给远端服务。
(2)第三方平台日志接入
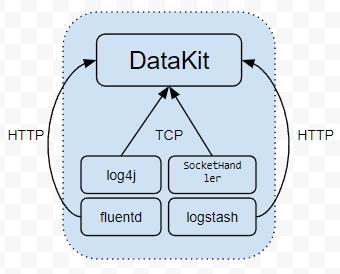
这种形式的特点是日志直接发送给 DataKit,中间无需落盘。
Sidecar 形式的日志采集
这种方式的采集实际上是综合了磁盘日志采集和日志远程推送俩种方式,具体而言,就是在用户的 Pod 中添加一个跟 DataKit 配套(即 logfwd)的 Sidecar 应用,其采集方式如下:

4、链路追踪
DataKit 当前支持多种广泛应用的 Trace 数据,如 zipkin/jaeger/otel/skywalking/ddtrace 等,只需要将对应的数据地址指向 Datakit 即可。
5、端行为
DataKit 支持全面收集前端的行为数据,包括 H5/Android/IOS/Fultter/React-native 等。
RUM(Real User Monitor)采集器用于收集网页端或移动端上报的用户访问监测数据。建议将 RUM 以单独的方式部署在公网上,不要跟已有的服务部署在一起(如 Kubernetes 集群)。因为 RUM 这个接口上的流量可能很大,集群内部的流量会被它干扰到,而且一些可能的集群内部资源调度机制,可能影响 RUM 服务的运行。
通常生产环境的 js 文件会经过各种转换和压缩,与开发时的源代码差异较大,不便于排错(debug)。如果需要定位错误至源码中,就得借助于sourcemap文件。
DataKit 支持这种源代码文件信息的映射,方法是将对应 js 的sourcemap文件进行 zip 压缩打包,命名格式为 --.zip,上传至<datakit安装目录>/data/rum/,这样就可以对上报的error指标集数据自动进行转换,并追加 error_stack_source 字段至该指标集中。
6、云原生安全
SChecker 插件,绝对安全的安全巡检器,lua 沙箱只读分析,支持 300+ 的安全事件发现,用户可自定义属于自己的规则文件及lib库。
一般在运维过程中有非常重要的工作就是对系统,软件,包括日志等一系列的状态进行巡检,传统方案往往是通过工程师编写shell(bash)脚本进行类似的工作,通过一些远程的脚本管理工具实现集群的管理。但这种方法实际上非常危险,由于系统巡检操作存在权限过高的问题,往往使用root方式运行,一旦恶意脚本执行,后果不堪设想。实际情况中存在两种恶意脚本,一种是恶意命令,如rm -rf,另外一种是进行数据偷窃,如将数据通过网络 IO 泄露给外部。
因此 Security Checker 希望提供一种新型的安全的脚本方式(限制命令执行,限制本地IO,限制网络IO)来保证所有的行为安全可控,并且 Security Checker 将以日志方式通过统一的网络模型进行巡检事件的收集。同时 Security Checker 将提供海量的可更新的规则库脚本,包括系统,容器,网络,安全等一系列的巡检。scheck 为Security Checker 的简写。
7、基于 eBPF的网络监控
DataKit eBPF 采集器支持收集面向主机/进程/容器的网络 4 层/7层的性能与异常数据。
eBPF 采集器,采集主机网络 TCP、UDP 连接信息,Bash 执行日志等。本采集器主要包含 ebpf-net 及 ebpf-bash 俩类:
ebpf-net:
数据类别: Network
由 netflow、httpflow 和 dnsflow 构成,分别用于采集主机 TCP/UDP 连接统计信息和主机 DNS 解析信息;
ebpf-bash:
数据类别: Logging
采集 Bash 的执行日志,包含 Bash 进程号、用户名、执行的命令和时间等;
CICD 追踪
DataKit 支持追踪 Gitlab pipeline/Jenkins的构建过程和相关指标日志。
通过配置 Gitlab Webhook,可以实现 Gitlab CI 可视化。Datakit 接收到 Webhook Event 后,是将数据作为 logging 打到数据中心的。
Jenkins 采集器可以通过接收 Jenkins datadog plugin 发出的 CI Event 实现 CI 可视化。
9、支持通过选举来进行差异化采集
在集群模式下,Datakit 能通过选举的方式来区分公共资源和专属资源的不同采集。对公共资源而言,多个 Datakit 会竞选其数据采集,但最终只有一个会获取到采集权,进而可避免对公共资源(比如 MySQL 指标)的重复采集以及可能的单点故障。
而对于专属资源,主要指主机相关的指标,如内存、磁盘等,它们都是由各个不同 Datakit 分别采集,不需要参与选举。
完整的数据处理语言 Pipeline
DataKit 内置简便的数据提取、处理引擎 Pipeline,用于提取非结构化数据,方便查询与统计。有以下特点:
简单,每一行就是数据处理,支持逻辑判断
全领域的数据处理,所有的收集数据均可以通过编写 Pipeline实现动态的数据预处理
丰富的函数支持
可通过内置的 Pipeline 功能直接操作 DataKit 采集的各种不同类型的数据,包括时序、日志、Tracing 等。同时还支持通过远程的方式编辑、调试 Pipeline,一键同步到所有 Datakit 上。
支持通过 git 来进行配置管理
由于大部分配置都是纯文本,Datakit 支持通过 Git 方式来管理这些配置,便于集群模式下的配置统一变更和同步。
强大的扩展性&开源兼容
自定义采集器
DataKit 包含定时触发用户自定义 python 采集脚本的一整套方案,支持自定义的 Python数据收集能力。
编写用户自定义脚本需要用户继承 DataKitFramework 类,然后对 run 方法进行改写。并且支持使用 git repo,一旦开启 git repo 功能,则 conf 里面的 args 里面填写的路径是相对于 gitrepos 的路径。
第三方接入
DataKit 支持第三方数据接入,例如:
Prometheus Exporter与Remote_Endpoint
Prom 采集器可以获取各种 Prometheus Exporters 暴露出来的指标数据,只要配置相应的 Exporter 地址,就可以将指标数据接入。并且支持监听 Prometheus Remote Write 数据。
(2)Filebeat/Flenutd
Elastic Beats 接收器目前支持接收 Filebeat 采集的数据。
(3)OpenTelemetry,Skywalking
灵活的部署模型,简单易用
DataKit 一键部署安装,全云平台支持,全操作系统支持,内置上百种数据集成,支持在安装阶段就自动开启基础数据采集,开箱即用。
基于主机
(1)若目标机器没有公网访问出口,DataKit 支持离线部署
(2)支持通过 Ansible 等方式来批量安装 DataKit
基于 Kubernetes
(1)支持在 K8s 中通过 DaemonSet 方式安装 DataKit
DataSinker-将数据写入到其他开源协议下的产品中
Sinker 是 DataKit 中数据存储定义模块。默认情况下,DataKit 采集到的数据是上报给观测云,但通过配置不同的 Sinker 配置,我们可以将数据发送给不同的自定义存储。
(1)InfluxDB:目前支持将 DataKit 采集的时序数据(M)发送到本地的 InfluxDB 存储
(2)M3DB:目前支持将 DataKit 采集的时序数据(M)发送到本地的 InfluxDB 存储(同 InfluxDB)
(3)Logstash:目前支持将 DataKit 采集的日志数据(L)发送到本地 Logstash 服务
更多功能
自监控调试能力
(1)DataKit 支持以交互式方式执行 DQL 查询,在交互模式下,DataKit 自带语句补全功能。
(2) DataKit 提供了相对完善的基本可观测信息输出,通过查看 DataKit 的 monitor 输出,我们能清晰的知道当前 DataKit 的运行情况。
(3)DataKit self 采集器用于 DataKit 自身基本信息的采集,包括运行环境信息、CPU、内存占用情况等。
联邦模式与代理模式
当 Datakit 无法访问外网时,可在内网部署一个代理将流量发送出来。
通过 DataKit 内置的正向代理服务
通过 Nginx 反向代理服务
当集群中只有一个被采集对象(如 Kubernetes),但是在批量部署情况下,多个 DataKit 的配置完全相同,都开启了对该中心对象的采集,为了避免重复采集,可以开启 DataKit 的选举功能。
全方位开源,安全保障
Datakit 已全方位开源,并且官方维护团队超过 10 人,可放心使用,安全有保障。
关于观测云
观测云,新一代 SaaS 化全链路数据可观测平台,实现统一采集、统一标签、统一存储和统一界面,带来全功能的一体化可观测体验。观测云能全环境高基数采集数据,支持多维度信息智能检索分析,及提供的强大的自定义可编程能力,使系统运行状态尽在掌控,故障根因无所遁形。聪明的团队会观测,可观测性用观测云。












TOM2025-07-09 18:3907-09 18:39

TOM2025-07-09 17:5807-09 17:58

TOM2025-07-09 17:5807-09 17:58

TOM2025-07-09 17:5507-09 17:55

TOM2025-07-09 17:5507-09 17:55






 点击下方菜单栏 “
点击下方菜单栏 “  ” 选择 “分享”, 把好文章分享出去!
” 选择 “分享”, 把好文章分享出去!

 为推荐给更多人
分享写下你的想法>
为推荐给更多人
分享写下你的想法>